智谱创始人唐杰透露:原生多模态模型将在数月内上线
 0
0


编辑 | 四月
智谱的原生多模态模型,到底什么时候来?
最近这个问题,在 X 上被直接推到了智谱创始人、清华大学教授唐杰面前。在今年 1 月的公开活动上,唐杰曾谈到,大模型如何把视觉、声音、触觉等多模态信息统一感知,也就是实现“原生多模态模型”,仍然是一个短板。
现在,他给出的答案是:数月内上线。

多模态对于智谱有多重要?
智谱是中国大模型牌桌上的头部玩家,路透社将其称之为 leading player。
今年 1 月,智谱登陆港股。上市以来股价从发行价 116.2 港元,一路涨到目前的约 1090 港元(今日最新收盘价),四个月涨幅 9 倍多,昨日市值更是突破 5000 亿港元;同期上市的 MiniMax 市值超过 2600 亿港元,约为智谱的一半。

资本市场给出如此高的叙事溢价,正在等待的也是智谱拼上最后一块关键拼图。GLM-5 发布后,智谱在 Coding 和 Long-running agent tasks(长时程代理任务)上发力,开源生态稳居全球第一梯队,但在多模态,尤其是原生多模态上,确实还需要给外界一个更明确的答案。
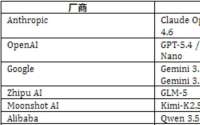
这个答案有多重要?看看现在的格局就知道:Kimi 今年 1 月底发布的 K2.5 已经是原生多模态架构;阿里 Qwen3.5-Omni 3 月上线,基于超过 1 亿小时音视频数据端到端预训练;GPT-4o 更是在去年 4 月就完成了原生多模态架构落地。
多模态的理解与构建,已成为头部模型拉开差距的最关键维度。
唐杰在推文里说清了底层逻辑:感知环境是完成长任务的基础,多模态不是功能附加,而是 Agent 真正落地的前提。
因此,补齐多模态不仅是支撑下一段资本叙事的必要条件,更是智谱走通技术路线闭环的必经之路。
数月之后,GLM 的旗舰模型会变成什么样子,现在有了第一个公开的时间坐标。
不止是智谱创始人
更重要的是,在给出“数月内上线”承诺的同时,唐杰还发了一篇长文,抛出了他对 AI 下一战场的核心判断:今年最可能突破的方向,不是单轮问答,也不是简单代码生成,而是 long-horizon tasks(长时程任务)。
这也印证了,智谱补齐得原生多模态,绝非单纯为了增加“看图、生成视频”的功能,而是将其作为 Agent 感知环境的触角,最终服务于长任务执行。
这篇文章不是“谈 AGI”的泛泛感想,而是智谱创始人在关键节点对大模型下半场的公开剧透。
唐杰还是谁?
他的头衔和成就,可能远比你熟知的要重得多。他是清华大学计算机系教授,是人工智能、图挖掘、知识图谱等领域的知名学者,他主导构建的 XLore 等大规模知识图谱,是中文知识工程的基石。
在产业界,他的影响力同样深远。
他曾担任北京智源人工智能研究院副院长,这一经历让他在中国 AI 产业顶层设计、大模型早期发展中扮演了关键角色。更令人津津乐道的是,Kimi 创始人、月之暗面创始人杨植麟在清华大学计算机系读本科期间,唐杰正是他的导师。
换句话说,唐杰在中国大模型创业圈和学术圈,绝不是旁观者,而是一个“源头型人物”。
所以他的这次判断,值得认真看看。
分享全文
以下是唐杰推文全文(中英对照):
Recent thoughts: The Shift to Long-Horizon Tasks
The most likely breakthrough this year will be in long-horizon tasks. We are moving toward a stage where Large Language Models (LLMs) learn to complete extended, complex missions by interacting with Agent environments. This is perhaps where the true value of LLMs lies. Take cybersecurity as an example: imagine a model that continuously hunts for software bugs and vulnerabilities. While it sounds like a search process, it's actually the model learning the high-level intuition and methodology of a professional hacker. Unlike humans, AI can run 24/7 without fatigue. It could potentially find exploits at a much higher frequency and claim bounties on platforms like HackerOne or BugCrowd. It sounds fun, but fundamentally, it's a revolution that displaces the hacker. If even hackers are being "disrupted," one can only imagine the impact on general programmers.
最近的一些想法:转向长时程任务
今年最有可能取得突破的领域是长期任务。我们正朝着大型语言模型(LLM)学习通过与智能体环境交互来完成扩展、复杂任务的阶段迈进。这或许才是 LLM 真正价值所在。
以网络安全为例:想象一个模型能够持续不断地搜寻软件漏洞。这听起来像是一个搜索过程,但实际上,该模型正在学习专业黑客的高级直觉和方法论。与人类不同,AI 可以全天候运行而不会感到疲劳,以更高的频率发现漏洞,并在 HackerOne 或 BugCrowd 等平台上领取赏金。
这听起来很有趣,但从根本上讲,这是一场颠覆黑客的革命。如果连黑客都受到了"颠覆",那么普通程序员将面临怎样的冲击?
From One-Person to None-Person Companies
Building on long-horizon capabilities, Autonomous Agent Systems (AAS) will inevitably become the next frontier. Last year, we were discussing the rise of the "One Person Company" (OPC). I didn't expect us to move so quickly toward the "None Person Company" (NPC). It's an ironic twist—we might all end up as NPCs in this new ecosystem.
从一人公司到无人公司
基于长远发展能力,自主代理系统(AAS)必将成为下一个前沿领域。去年,我们还在讨论"一人公司"(OPC)的兴起。没想到我们会如此迅速地迈向"无人公司"(NPC)。
这真是一个讽刺的转折——在这个新生态里,我们最终可能都会成为 NPC。
Engineering the Impossible: Memory and Learning
To realize the vision above, we must solve three technical pillars: Memory, Continual Learning, and Self-Judging. I used to think these would require massive paradigm shifts and years of research. However, the pressure from both the technical and application sides is so intense that we are seeing these capabilities emerge through ingenious engineering "tricks": Memory: Long context windows (1M+) and RAG have significantly bridged the gap. Continual Learning: While true continual learning remains difficult, the release cycles are shrinking. Global models are updated monthly; domestic models are catching up. If we reach weekly updates by next year, it will effectively function as continual learning. Self-Judging: This remains the most elusive, yet models like Opus 4.7 are already demonstrating early self-correction and judgment capabilities.
化不可能为可能:记忆与学习
要实现上述愿景,我们必须解决三个技术支柱:记忆、持续学习和自我评判。我过去认为这些需要巨大的范式转变和多年的研究。
然而,来自技术和应用方面的压力如此之大,以至于我们看到这些能力正通过巧妙的工程"技巧"涌现出来:
记忆:长上下文窗口(1M+)和 RAG 显著缩小了差距。
持续学习:虽然真正的持续学习仍然困难重重,但发布周期正在缩短。全球模型每月更新一次;国内模型也在迎头赶上。如果明年能实现每周更新,就能有效地实现持续学习。
自我评判:这仍然是最难以捉摸的,但像 Opus 4.7 这样的模型已经展现出早期自我纠正和判断能力。
The Self-Evolving Endgame
The most difficult—and most promising—path is Self-Evolution. The current wave is incredibly fierce. I suspect that models like Claude may have already achieved a baseline for self-training: writing their own code, cleaning their own data, generating synthetic data, and then training on it. It might "waste" some compute, but it saves the most precious resources: human labor and time. In the LLM era, speed is everything. Rapid iteration is what creates the cognitive gap between leaders and followers. Claude's rumored 2-million-chip cluster for next year is likely dedicated to exactly this: autonomous model self-training.
Technical Summary: 1M Context: Necessary baseline. Memory & Continual Learning: Prerequisites, likely solved first via "tricky" engineering. Harnessing Environments: The breakthrough point. Self-Judging: The tipping point. Full Self-Training: The endgame.
自我演化的终局
最艰难也最有前途的道路是自我进化。当前的浪潮势头异常强劲。我怀疑像 Claude 这样的模型可能已经达到了自我训练的基准:编写自己的代码、清理自己的数据、生成合成数据,然后用这些数据进行训练。
这或许会"浪费"一些计算资源,但却节省了最宝贵的资源:人力和时间。在大模型时代,速度至关重要。快速迭代正是造成领导者和追随者之间认知差距的关键。据传 Claude 明年将要使用的拥有 200 万个芯片的集群,很可能正是为此而建:自主模型的自我训练。
技术路线概要: 1M 上下文:必要的基线。
记忆与持续学习:前提条件,很可能首先通过"巧妙的"工程手段来解决。
利用环境:突破点。 自我评判:转折点。
完全自主训练:最终目标。
Redefining AGI and the Industry
If this is the road to AGI, then AGI's definition should be the sum of all human collective intelligence, not just an individual's intelligence. It must possess the creative capacity to produce something as profound as the "Theory of Relativity"—meeting the bar set by Hassabis. During this transition, every APP will need to be reconstructed as AI-native. In fact, we might move past the concept of APPs entirely. The most significant challenge will be the reconstruction of the operating system itself. In the future, you won't see a traditional desktop; you will see an LLM OS, where applications are "generated on demand." This challenges the 80-year-old Von Neumann architecture and represents a total upheaval of the computer science industry.
重新定义 AGI 和行业
如果这就是通往 AGI 的道路,那么 AGI 的定义应该是全人类集体智慧的总和,而不仅仅是个体的智慧。它必须具备创造能力,能够创造出像"相对论"那样意义深远的理论——达到哈萨比斯设定的标准。
在此转型过程中,所有应用程序都需要重构为 AI 原生应用。事实上,我们甚至可能彻底摒弃应用程序的概念。最大的挑战将是操作系统本身的重构。未来你将不再看到传统的桌面系统,而是看到 LLM 操作系统,其中应用程序是"按需生成的"。这将挑战沿用 80 年的冯·诺依曼架构,彻底颠覆计算机科学行业。
The Irreversible Wave
From completing long-horizon tasks to fully autonomous operations, every sector—Security, Finance, Law, E-commerce—will be reshaped. Many friends have reached out lately, asking how to transform their enterprises to keep pace with AI. But few truly realize that this irreversible process has already begun. As this massive technical wave hits, we must be prepared to act, but we must also start thinking seriously about how to regulate it.
不可逆的浪潮
从完成长期任务到实现完全自主运营,各个领域——安全、金融、法律、电子商务——都将发生重塑。最近很多朋友联系我,询问如何转型才能跟上 AI 的步伐。
但很少有人真正意识到,这一不可逆转的进程已经开始。随着这股技术浪潮的到来,我们必须做好应对准备,同时也必须认真思考如何对其进行监管。
声明:本文为 AI 前线编译,不代表平台观点,未经许可禁止转载。
会议推荐
Agent 从 Demo 到工程化还差什么?安全与可信这道坎怎么过?研发体系不重构,还能撑多久?
AICon 上海站 2026,13 大重磅专题已上线,诚挚邀请你登台分享实战经验。AICon 2026,期待与你同行。快来扫码锁定 8 折专属席位或提交演讲议题
今日荐文

你也「在看」吗?
热搜
热门跟贴
相关推荐
-
唐杰深夜发文,AI从工具到劳动力只差这一步
 字母榜 10跟贴
字母榜 10跟贴 -
知名AI交易团队:多智能体架构如何打造华尔街级交易系统
孤酒老巷QA 1跟贴
-
国产GPU组了个开源局,把SGLang等核心开发者都摇来了!
量子位
-
2600万参数模型跑通手机端工具调用,Gemini蒸馏版Needle开源
硬核玩家2哈
-
AI编程工具卷疯了:Grok Build意外曝光、DeepSeek-TUI抢占终端,开发者如何守住自己的“独特性”?
CSDN
-
Anthropic产品负责人:AI将在你意识到需求前就预判它
野生运营
-
17个AI代理组团写代码,Anthropic生态长出"软件工厂"
固件更新中
-
阿里AI平台“悟空”开启规模化放量
网易智能
-
一款名叫“飞象老师”的教师AI大模型应用在世数会受到关注,根据教案能直接生成一堂互动课
学申论的谈妹
-
CZ 迈阿密演讲:加密货币将成为 AI 智能体的原生货币
吴说
-
全球AI付费率仅0.3%!张予彤拆解Kimi技术、人才、开源三重逻辑
每日经济新闻
-
90 后正在掌管中国 AI,凭实力活成了「爽文」主角
爱范儿
-
从智能体到赛博员工,生产力智能涌现
机器之心Pro
-
实测两款AI工具后,我开始认真考虑“一人公司”了
智东西 5跟贴
-
奥特曼预言与现实相差几何?12个顶级模型“创业”一年,仅3个存活
钛媒体APP
-
5大看点拿走不谢!离中国AIGC产业峰会只有5天啦
量子位
-
商汤SenseNova U1深度拆解,原生统一架构终结缝合时代
机器之心Pro
-
江苏省公布无人驾驶航空器适飞空域范围
澎湃新闻 45跟贴
-
一家创业公司要用AI重做资讯产品
经济观察报
-
宇树秀肌肉给马斯克看
虎嗅APP 64跟贴