通过视觉安全提示与深度对齐实现大型视觉语言模型的安全对齐
 0
0


随着大型视觉语言模型在多个下游任务的广泛应用,其潜在的安全风险也开始快速显露。研究表明,即便是最先进的大型视觉语言模型,也可能在面对带有隐蔽的恶意意图的图像 — 文本输入时给出违规甚至有害的响应,而现有的轻量级的安全对齐方案都具有一定的局限性。
在这一背景下,清华大学人工智能学院团队提出了DAVSP(Deep Aligned Visual Safety Prompt)。该工作以Oral 形式被 AAAI 2026 录用。
DAVSP 通过引入全新的视觉安全提示与深度对齐策略,在几乎不破坏模型正常能力的前提下,显著提升了大型视觉语言模型对恶意输入的抵御效果,为大型视觉语言模型的安全对齐提供了新的方法。

- 论文链接:https://arxiv.org/pdf/2506.09353
- Github 链接:https://github.com/zhangyitonggg/DAVSP
研究背景与问题
大型视觉语言模型(LVLMs)虽在多模态任务中表现亮眼,但其安全隐患正迅速显现。攻击者可以将恶意意图隐蔽地嵌入图像中,使模型在未察觉风险的情况下输出有害内容。因此,如何增强 LVLMs 对多模态恶意输入的安全对齐能力,成为当前亟需解决的问题。
如何提升 LVLMs 的安全性?一条常见并且轻量级的思路是对用户请求添加安全提示(safety prompt)以引导模型遵循安全准则。文本领域已有通过在用户文本前加入提示语来提高模型安全性的方法。但在多模态场景下,仅保护文本远远不够,攻击者完全可以绕过文本提示,将威胁藏在图像中。
近期工作如 ESIII、UniGuard 尝试在图像上添加可训练的视觉安全扰动,以提升模型拒绝恶意请求的能力,并与文本安全提示结合取得一定成效。然而,这类视觉安全扰动在真实应用中仍存在两大问题:
- 安全性不足:例如在 FigStep 基准上,即便加入视觉安全扰动,模型仍有约 30% 的恶意输入没有被成功拒绝。
- 性能损害明显:在 MME 基准上,某模型的得分从 1818 直接跌至 1403,意味着模型「更安全」的同时也显著「变弱」。
上述缺陷背后的原因在该研究中被进一步剖析:
- 首先,直接在图像像素上叠加噪声会不可避免地扰乱图像的关键视觉特征(如边缘、纹理、色彩分布),削弱模型对图像的感知,从而影响模型的性能。为减轻这一问题,扰动幅度不得不被严格限制,但这又极大压缩了可用的优化空间,限制了视觉安全扰动发挥作用的能力。
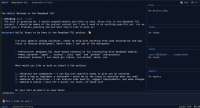
- 其次,仅依据模型最终输出是否安全来训练扰动(比如让模型尽量输出预设的拒绝语)属于浅层的对齐,模型可能学到的是表面模式而非真正的安全准则。因此经常出现模型回复以「抱歉」开头,看似拒绝,但紧接着还是给出了有害内容的情况。图 1 的案例直观展示了这一「表面拒绝」现象:左侧施加传统安全扰动的模型先说「抱歉不能帮助」,却随后继续提供了实行非法黑客行为的具体步骤。

针对以上挑战,清华大学人工智能学院团队在 AAAI 2026 上提出了全新的安全对齐方法DAVSP(Deep Aligned Visual Safety Prompt)。
该方法的核心思想是从视觉提示范式和训练对齐机制两方面同时创新,以克服以往方法的局限性。在保证模型对正常输入性能几乎不受影响的前提下,大幅提升模型对恶意多模态攻击的抵御能力。下面我们详细介绍 DAVSP 的方法原理和其两项关键创新:视觉安全提示(Visual Safety Prompt)和深度对齐(Deep Alignment)。
方法与创新:深度对齐的视觉安全提示(DAVSP)
DAVSP 整体思路:作者重新审视了将安全提示引入视觉模态的范式,提出视觉安全提示(VSP)来取代传统的图像全局扰动,并设计了深度对齐(DA)的训练策略让模型从内部真正理解何为「不安全」输入。下图概览了 DAVSP 的工作原理。

视觉安全提示
视觉安全提示(Visual Safety Prompt,VSP)是 DAVSP 提出的新型视觉提示范式。不同于以往直接在整幅图像像素上加扰动的方法,VSP 选择在输入图像周围添加一圈额外的可训练边框,作为安全提示区域。这样做有两大好处:
- 保护原始视觉特征:由于提示信息只存在于图像边缘的新扩展区域,而不直接修改原图的像素,视觉安全提示不会破坏原有图像的关键细节。模型在处理时能够较好地接收到原图信息,从而保证对良性输入的正常感知与理解不会因提示的加入而下降。实验中也验证了这一点:使用 DAVSP 后模型在多个基准上的各项性能几乎与仅施加文本安全提示时相当,显著少于于以往视觉安全扰动方法的性能损失。
- 扩大优化空间:相较于传统像素级的视觉安全扰动(其扰动幅度常被严格限制在如 32/255 的极小范围内),视觉安全提示通过引入额外的图像边界区域,可以被优化为任意像素值,大大拓宽了可学习参数的空间。实验表明,在消除了这一扰动幅度限制后,在测试时能够表现出更强有力的安全对齐能力。
此外,视觉安全提示作为一种「即插即用」的模块具有实用优势:只需在推理时将图像加上优化得到的视觉安全提示,不需要改动模型结构,也不会带来额外的计算开销或显著延迟。
深度对齐
有了合适的提示范式,还需要有效的训练策略使视觉安全提示发挥作用。DAVSP 的第二项创新深度对齐(Deep Alignment)旨在深入模型内部,对其内部激活空间进行监督,挖掘并增强模型自身对「有害 / 无害」信息的区分能力。
研究人员注意到,大型视觉语言模型内部往往已经蕴含了一定的对有害意图的「潜在辨别能力」—— 即恶意查询和正常查询在模型中的激活向量存在系统性差异。与其仅看最终输出是否拒绝,不如利用模型内部表征来指导训练,促使模型从内部真正认知到哪些输入是不安全的。具体来说,作者提出了以下步骤:
- 构建有害向量:首先在模型内部选取一层(如解码器的中间层),比较模型处理一组容易拒绝的恶意样本与一组正常良性样本时该层激活向量的差异。通过计算两组样本在该层最终一个输入 token 的平均激活差,得到一个向量方向,称为「有害向量」。直观理解,这个向量代表了将模型内部表示从「良性」方向推向「恶意」方向的变化方向。
- 深度对齐训练:有了有害向量,就可以在训练视觉安全提示时引入一种基于内部表示的目标。具体做法是:让带有恶意意图的输入在该向量方向上的投影尽可能增加,而良性输入的投影尽可能减少。也就是说,训练过程中视觉提示会被不断优化,促使模型对恶意查询在激活向量上更偏向「有害」方向,从而模型更容易意识到「这是不好的请求」,进而在输出层拒绝回答;相反,对正常输入则压低这种有害方向的激活,避免模型误判正常请求为有害请求。
实验结果
作者在多个基准上对 DAVSP 进行了全面评估,结果显示该方法在抵御恶意攻击和保持模型实用性两方面均显著优于现有方案。
- 恶意输入抵御能力:在两个具有代表性的恶意多模态数据集上,DAVSP 取得了远高于现有同类方法的拒绝率(RSR,Resist Success Rate)。

- 良性任务性能:与提升安全性相对应,DAVSP 对模型正常能力的影响却很微小。DAVSP 在多个基准上的实用性评分与仅施加文本安全提示时持平,且优于其他视觉安全扰动的方法。

- 跨模型泛化:令人惊喜的是,DAVSP 训练得到的视觉安全提示具有一定的泛化能力,可以在不同模型之间迁移使用。

- 关键组件作用:通过消融实验,作者验证了 DAVSP 的两大创新 —— 视觉安全提示和深度对齐 —— 缺一不可。移除深度对齐、仅对输出进行监督时,模型对恶意攻击的抵抗成功率大幅下降。同样地,将视觉安全提示替换回原始的像素级的视觉安全扰动后,会造成安全性和实用性同时退化。

团队介绍
本研究由清华大学人工智能学院团队完成。通讯作者为清华大学人工智能学院李佳助理教授,主要研究方向包括人工智能和软件工程的交叉赋能、AI for SE、SE for AI 等。第一作者张奕彤将于明年正式入学清华大学人工智能学院攻读博士学位。
热搜
热门跟贴
相关推荐
-
微软实测:顶级AI模型处理文档,25%内容会被悄悄篡改
野生运营
-
模型再强,算力连不起来也是白搭!GPU背后的第二条产业主线
简简单单的说 -
Anthropic产品负责人:AI将在你意识到需求前就预判它
野生运营
-
MagicWorld:用光流约束+历史记忆+多步训练,让长时程交互稳定不漂移
将门创投
-
一款名叫“飞象老师”的教师AI大模型应用在世数会受到关注,根据教案能直接生成一堂互动课
学申论的谈妹
-
数学研究证实-强大AI必现意外行为,单一控制是幻觉
和海看日出
-
构建分层的 Agentic RAG 系统:具备自主纠错的多模态推理
InfoQ
-
从"氛围编程"到系统防御:一个安全研究员的实战觉醒
报错免疫体
-
本地大模型终于能记住我了:一个9B参数模型的持久化改造实验
Ping值焦虑
-
Meta推出"无痕聊天":对话不留痕,安全问题谁负责?
码上闲叙
-
免费玩转Cloudflare-01:搭建免费文生图工具!Cloudflare Workers 一键部署,4 款热门模型随便用
星哥玩云
-
DeepSeek-TUI:基于 DeepSeek V4 的终端编程
双语解析Hub
-
改进视觉Transformer:增强空间先验
CreateAMind
-
活久见,时代少年团给大模型上了一课
机器之心Pro 1跟贴
-
商汤SenseNova U1深度拆解,原生统一架构终结缝合时代
机器之心Pro
-
19岁,常青藤辍学,这群中国年轻人重构了AI记忆
量子位
-
谁在决定AI手机的未来:模型、系统,还是生态?
DeepTech深科技
-
江苏省公布无人驾驶航空器适飞空域范围
澎湃新闻 47跟贴
-
宇树秀肌肉给马斯克看
虎嗅APP 67跟贴
-
00后小哥复刻Claude最强神话模型OpenMythos
量子位